オープンソースの分散処理システムで、ビッグデータに均一のバッチ処理
- Home
- エンタープライズソリューション
- Hadoop
Hadoopとは
Hadoopは、オープンソースの分散処理システムで、膨大なデータに均一のバッチ処理をするのに向いています。
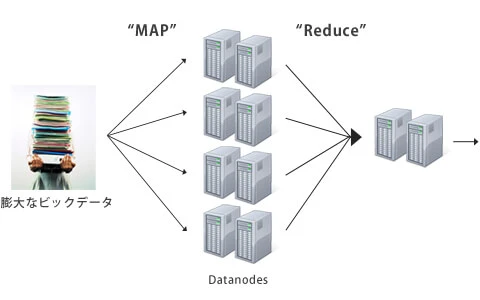
多数(通常は数百台以上)の「データノード」と呼ばれる小さなサーバに分析対象のデータを配付し(この処理を“Map”と呼びます)、データノードで処理されたデータを回収後に統合(この処理を“Reduce”と呼びます)して、一つの計算結果にまとめるという流れです。
Hadoopの特徴
Hadoopは以下のようなビッグデータ処理システムに最適です。
- 毎日何千件と届くメールを分析し、お問い合わせ内容の傾向分析に…
- Twitterなどのソーシャル・ネットワークに流れる大量のデータを分析し、トレンドの分析に…
- ウェブサイトのアクセスログを分析し、アクセス傾向分析に…
- 膨大な書類を分析し、検索のためのキーワードリスト作成と検索インデックスの作成に
当社では、Hadoop以外にも、オープンソース系のKVS(Key-Value-Store)などの非ストラクチャードデータベース、インメモリデータベースについても取り扱っておりますので、お問い合わせください。
Hadoopによる分散処理のイメージ
HadoopはApacheプロジェクトによるオープンソース・ソフトウェアです。詳細はApache Hadoopのサイトをご覧ください。
本ページはHadoopを活用した構築事例としてご紹介しております。